[翻译]ruby设置实例变量性能表现(instance variable performance)
原文
让我们从一个奇怪的Ruby基准测试开始:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
require "benchmark/ips"
class Foo
def initialize forward
forward ? go_forward : go_backward
end
ivars = ("a".."zz").map { |name| "@#{name} = 5" }
# define the go_forward method
eval "def go_forward; #{ivars.join("; ")} end"
# define the go_backward method
eval "def go_backward; #{ivars.reverse.join("; ")} end"
end
# Heat
Foo.new true
Foo.new false
Benchmark.ips do |x|
x.report("backward") { 5000.times { Foo.new false } }
x.report("forward") { 5000.times { Foo.new true } }
end
这段代码定义了一个设置大量实例变量的类, 但实例变量的设置顺序取决于传递给构造函数的参数。当我们传递true时,它从”a”到”zz”定义实例变量,当我们传递false时,它从”zz”到”a”定义实例变量。
以下是在我的计算机上得出的基准测试结果:
1
2
3
4
5
6
7
$ ruby weird_bench.rb
Warming up --------------------------------------
backward 3.000 i/100ms
forward 2.000 i/100ms
Calculating -------------------------------------
backward 38.491 (±10.4%) i/s - 192.000 in 5.042515s
forward 23.038 (± 8.7%) i/s - 114.000 in 5.004367s
出于某种原因,由后往前定义实例变量比由前往后定义实例变量运行得更快。我们将在这篇文章中讨论个中原因。至于现在,只需知道,如果你需要更高效的代码,请始终从后至前定义实例变量(只是开玩笑,千万不要这样做)。
实例变量是如何存储的?(How Are Instance Variables Stored?)
在Ruby中(特别是MRI),对象实例都指向一个数组,而一个实例的所有变量都存储在该数组中。显然,我们一向是按名称而不是数组索引来引用实例变量,因此,Ruby 会持有一个”名称 - 索引”(names to indexes)的映射,该映射存储在对象的类上。
假设我们有如下代码:
1
2
3
4
5
6
7
8
9
10
class Foo
def initialize
@a = "foo"
@b = "bar"
@c = "baz"
@d = "hoge"
end
end
Foo.new
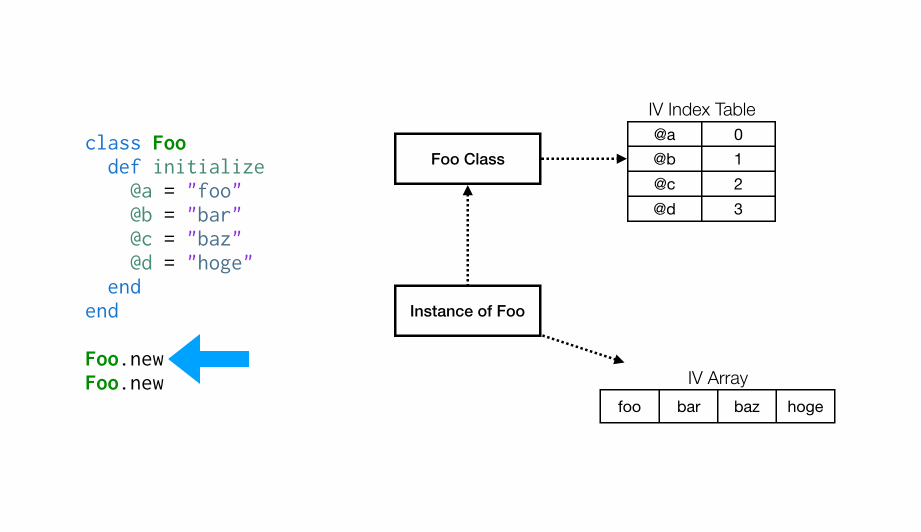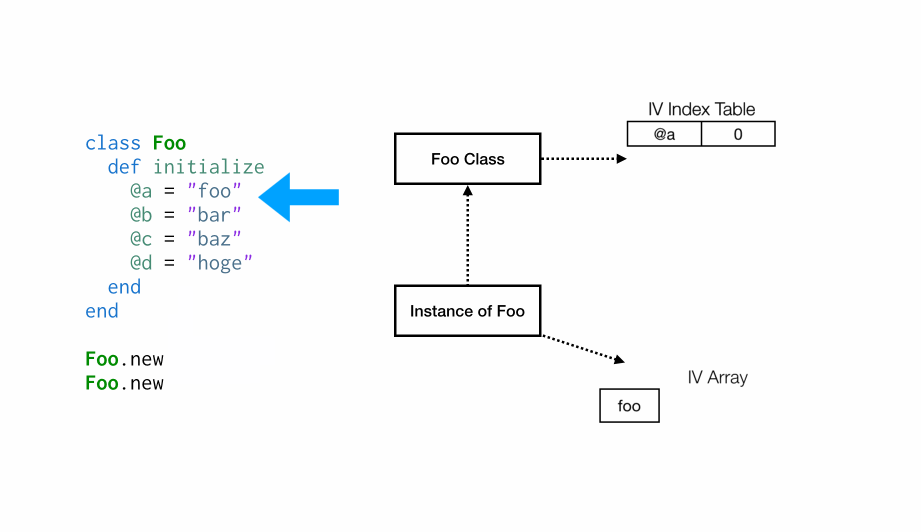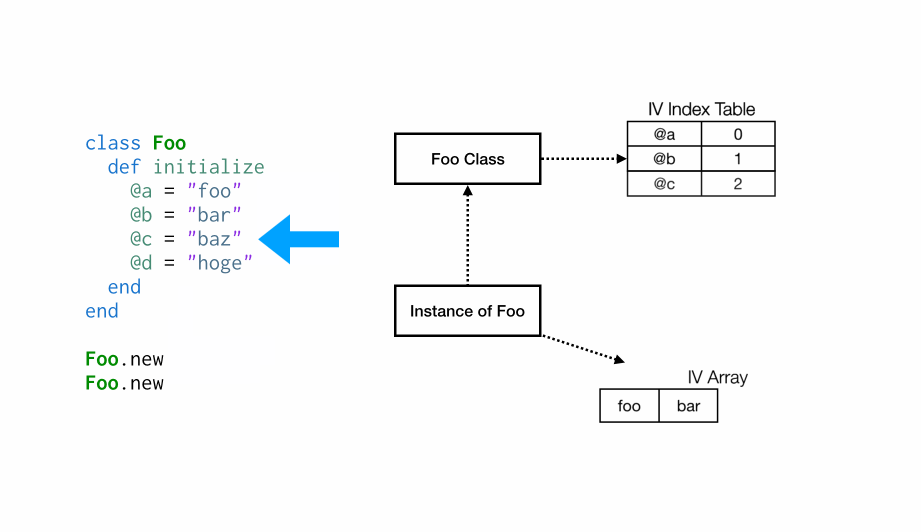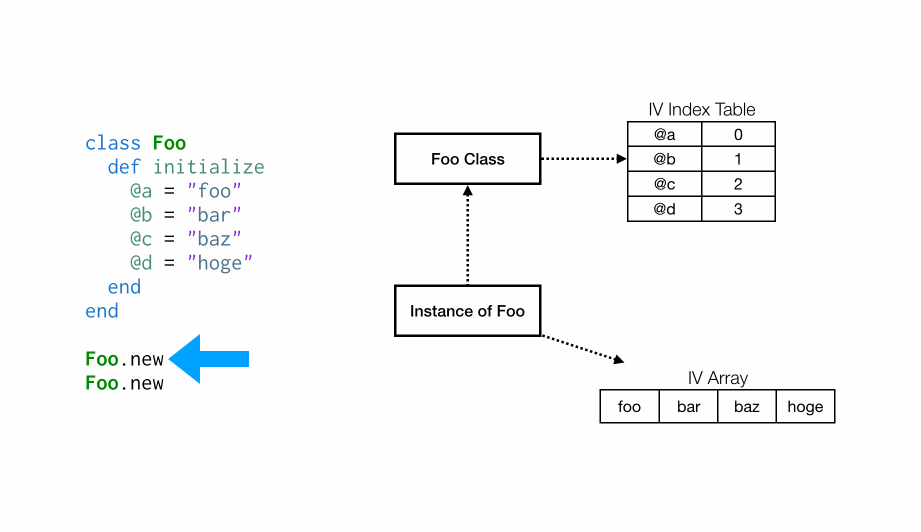
在内存模型内,上文所述的类、对象、实例变量数组和索引表 关系会如下所示:
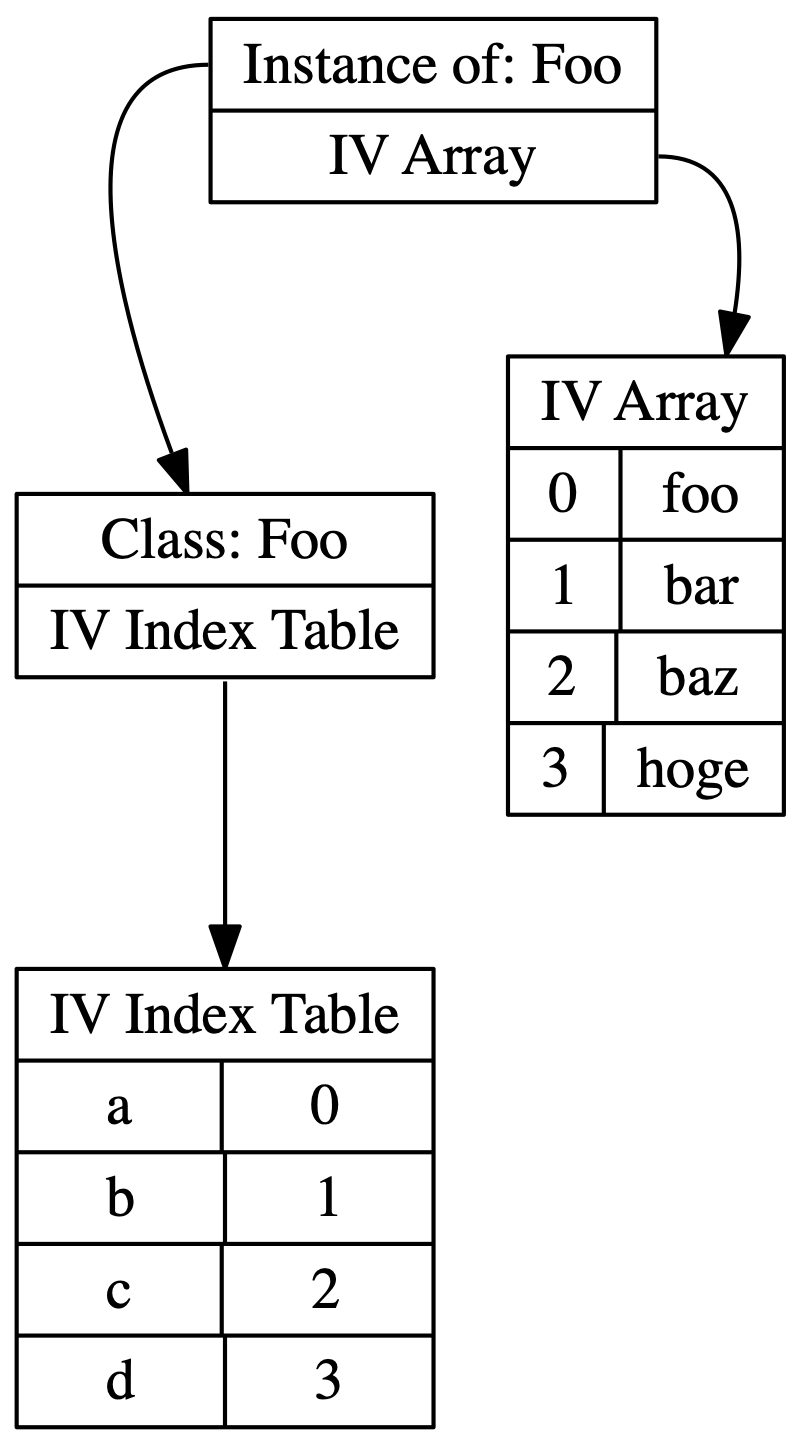
类会指向一个被称为”IV index Table”的”names to indexs”映射。IV index Table会成对的包含实例变量的名称及其对应的查找该实例变量的索引在其中。
相关实例将指向类,并指向实际包含实例变量值的一个数组。
为什么要不辞辛苦的将实例变量的名称映射到数组偏移量呢?因为访问数组元素比从哈希查找所需的内容要快得多。我们有时确实需要从哈希中查找数组的元素(实例变量的索引),但实例变量具有自己的内联缓存,因此不是每次都需要执行一次哈希查寻。
在动画中演示实例变量的设置(Setting Instance Variables in Slow Motion)
我们将进行两遍设置实例变量的操作,以展示在设置实例变量时究竟会发生什么。
示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
class Foo
def initialize
@a = "foo"
@b = "bar"
@c = "baz"
@d = "hoge"
end
end
Foo.new
Foo.new
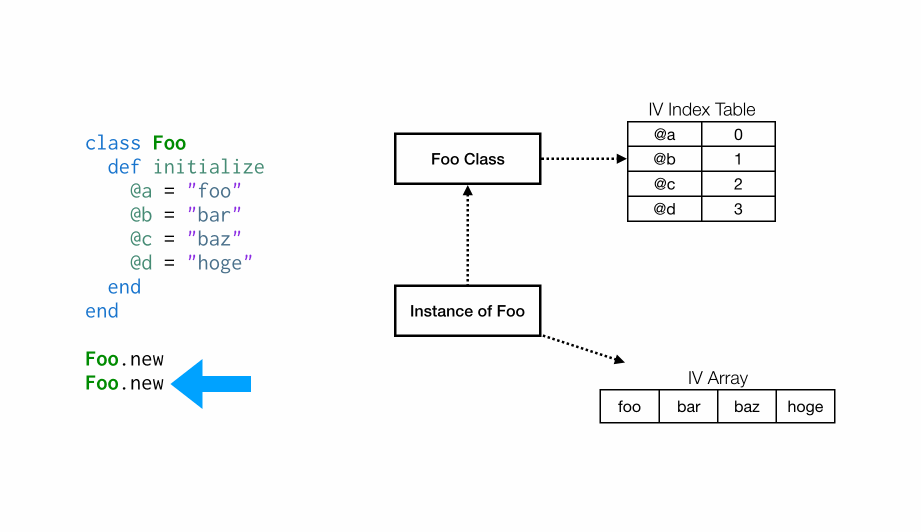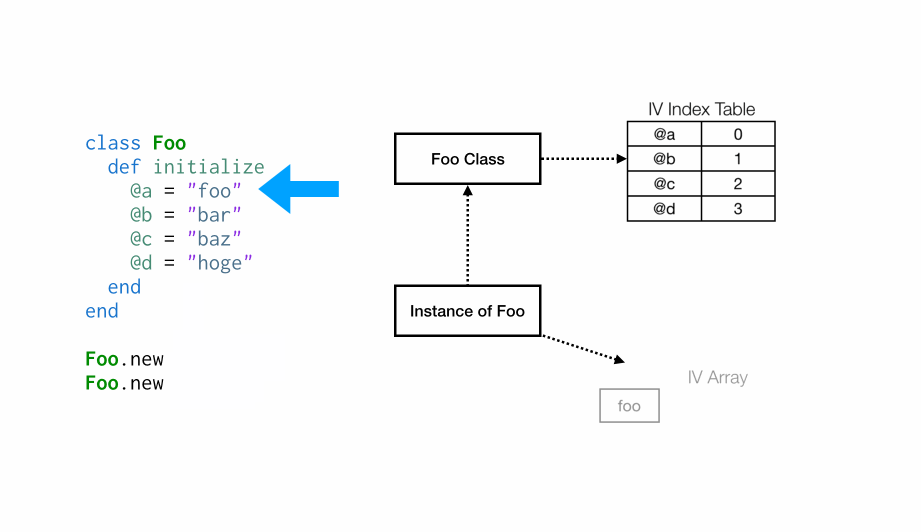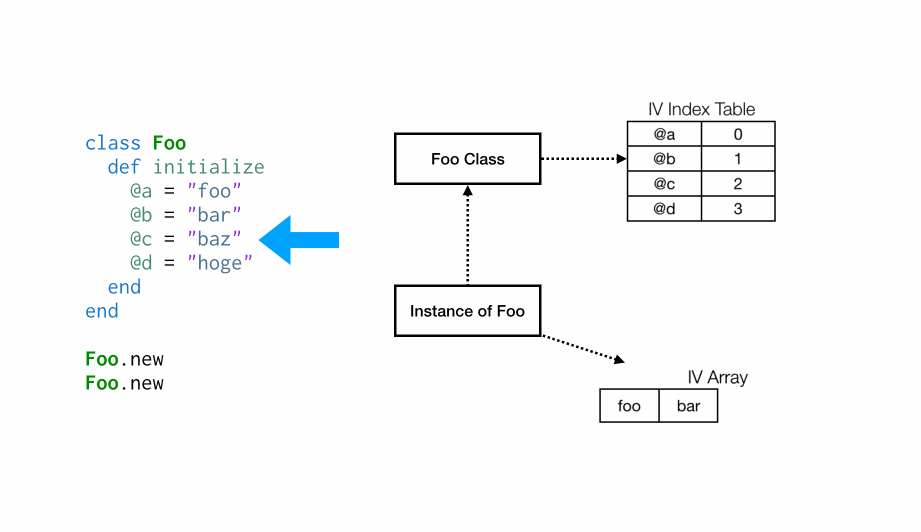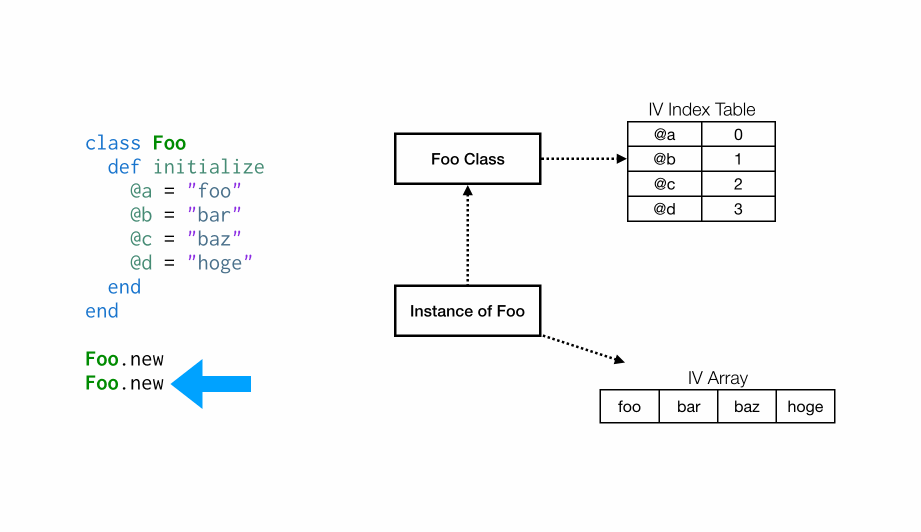
Ruby 会延迟创建实例变量索引表,因此直到代码第一次执行它才真正存在。以下 GIF 展示了首次Foo.new时的执行流程:
 第一次执行initialize时,Foo类没有与之关联的实例变量索引表(IV Index Table),因此当设置第一个实例变量
第一次执行initialize时,Foo类没有与之关联的实例变量索引表(IV Index Table),因此当设置第一个实例变量@a时,将创建一个新的索引表(IV Index Table),然后将@a的索引设置为0,然后在实例变量数组(IV Array)索引 0 处设置其值为“foo”。
当代码执行到设置实例变量@b时,它在索引表中没有对应的条目,因此我们添加一个指向位置 1 的新条目,然后将数组中的位置 1 设置为”bar”。
方法中的每个实例变量重复这个过程。
现在,让我们来看看第二次调用Foo.new时会发生什么:
 这一次,这个类已经有一个与其关联的实例变量索引表(IV Index Table)。设置实例变量
这一次,这个类已经有一个与其关联的实例变量索引表(IV Index Table)。设置实例变量@a时,发现其已经存在于索引表,值为 0,因此我们将在实例变量列表中索引为 0的地方设置为”foo”。
当我们看到实例变量@b时,它在索引表中已经有一个位置为 1 的条目,因此我们将”bar”设置为在实例变量列表中的位置 1。
方法中的每个实例变量重复会这个过程。
我们可以使用ObjectSpace.memsize_of来观察到索引表的延迟创建:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
require "objspace"
class Foo
def initialize
@a = "foo"
@b = "bar"
@c = "baz"
@d = "hoge"
end
end
p ObjectSpace.memsize_of(Foo) # => 520
Foo.new
p ObjectSpace.memsize_of(Foo) # => 672
Foo.new
p ObjectSpace.memsize_of(Foo) # => 672
在实例化第一个实例之前,Foo 的大小较小,但在后续内存分配过程中仍保持相同大小。漂亮!
让我们使用以下代码再做一个示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Foo
def initialize init_all
if init_all
@a = "foo"
@b = "bar"
@c = "baz"
@d = "hoge"
else
@c = "baz"
@d = "hoge"
end
end
end
Foo.new true
Foo.new false
在Foo.new true的第一次调用之后,Foo类将关联一个实例变量索引表,就像前面的示例一样。@a将与位置 0 相关联,@b与位置 1,等等。但是,在Foo.new false的第二次分配中会发生什么?
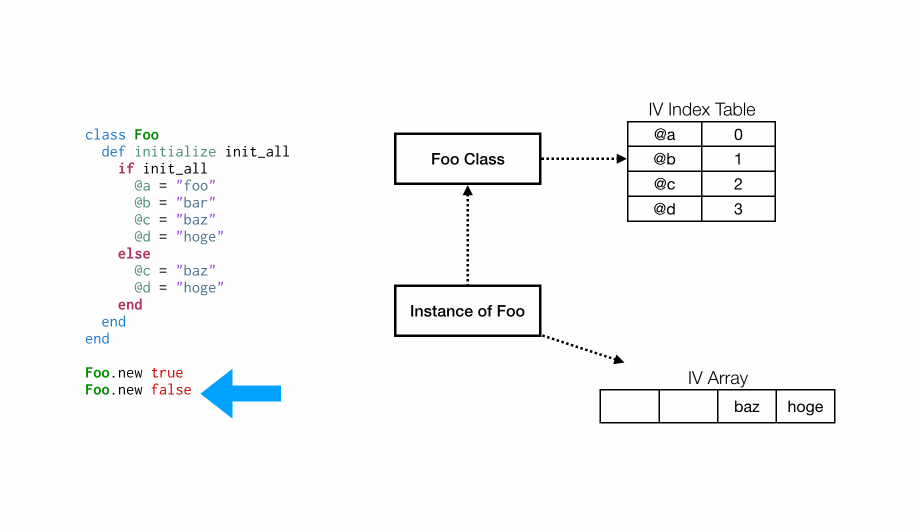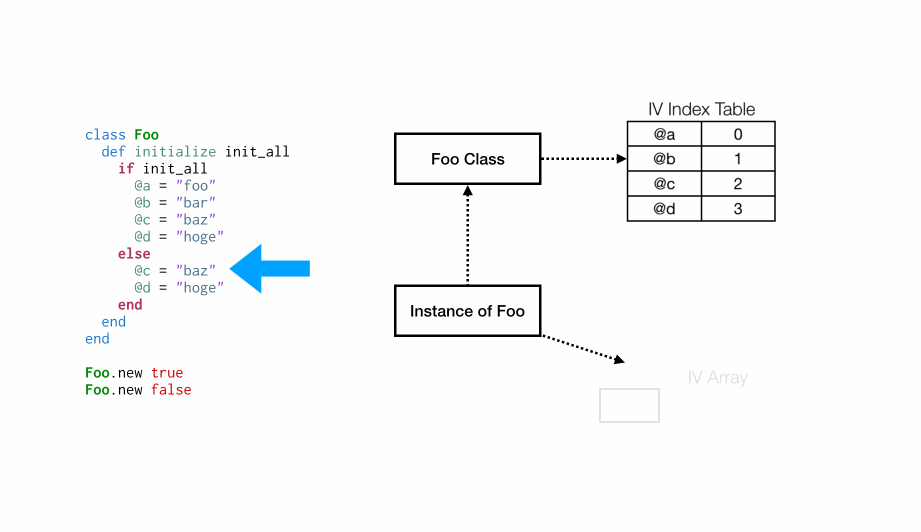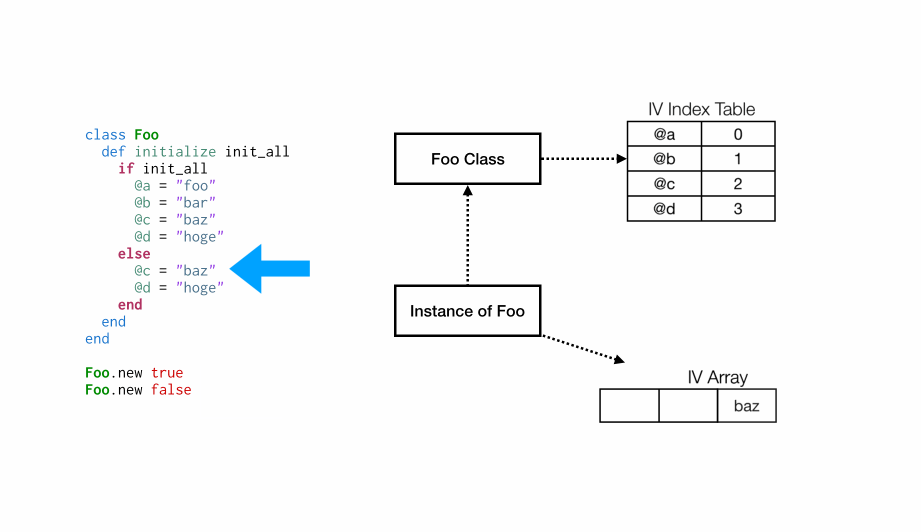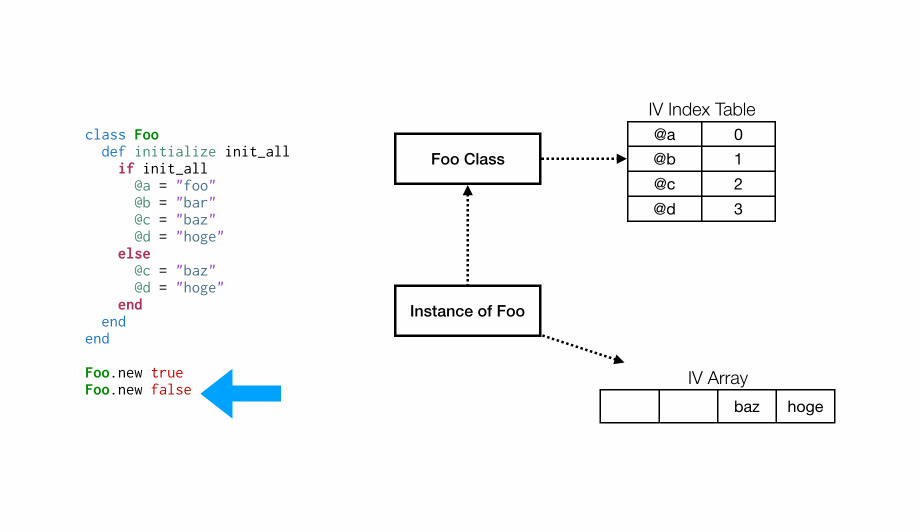 在这种情况下,我们已经有一个与类关联的索引表,但
在这种情况下,我们已经有一个与类关联的索引表,但@c与实例变量数组中的位置 2 相关联,因此我们必须对数组进行一次扩容,使位置 0 和 1 保存未被设置的状态(Ruby 内部将它们设置为Qundef)。然后,@d与位置 3 相关联,并像以往步骤一样设置。
上述的重点是实例变量列表必须扩张到索引偏移所需的宽度。现在,让我们来研究列表的扩容方式。
实例变量列表的分配和扩容(Instance Variable List Allocation and Expansion)
我们已经了解到实例变量索引表的创建方式。现在让我们专注于实例变量列表。这一列表与实例相关联,并保持着我们对实际实例变量值的引用。
此列表是延迟地分配和扩容,在它需要容纳更多的值的时候。链接内的源码描述了数组的容量会如何地增长。
我已经将该函数转换为 Ruby 代码,并添加了一些注释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def iv_index_tbl_newsize(ivup)
index = ivup.index
newsize = (index + 1) + (index + 1)/4 # (index + 1) * 1.25
# if the index table *wasn't* extended, then clamp the newsize down to
# the size of the index table. Otherwise, use a size 25% larger than
# the requested index
if !ivup.iv_extended && ivup.index_table.size < newsize
ivup.index_table.size
else
newsize
end
end
IVarUpdate = Struct.new(:index, :iv_extended, :index_table)
index_table = { a: 0, b: 1, c: 2, d: 3 } # table from our examples
# We're setting `@c`, which has an index of 2. `false` means we didn't mutate
# the index table.
p iv_index_tbl_newsize(IVarUpdate.new(index_table[:c], false, index_table))
返回值iv_index_tbl_newsize用于确定实例变量数组所需的内存量。正如代码展示的一样,其返回值基于实例变量的索引,且该索引基于我们索引表中得到的值。
如果索引表发生突变,则实例变量列表可能会无边界地增长。但是,如果索引表未发生突变,则数组大小将依次随着索引表的大小增长后紧缩。
这意味着,当我们第一次分配一个特定的Ruby对象时,它可能大于后续分配所需的内存。同样,我们可以使用ObjectSpace.memsize_of来观察此行为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
require "objspace"
class Foo
def initialize
@a = "foo"
@b = "bar"
@c = "baz"
@d = "hoge"
end
end
p ObjectSpace.memsize_of(Foo.new) # => 80
p ObjectSpace.memsize_of(Foo.new) # => 72
p ObjectSpace.memsize_of(Foo.new) # => 72
第一个分配较大,因为这是我们第一次”看到”这些实例变量。后续分配较小,是因为 Ruby 会压缩实例可变数组大小。
观测实例变量数组的增长(Watching the Instance Variable Array Grow)
让我们再做一次实验,然后再讨论为什么文章开始时的基准测试会以那样的一种的方式执行。在这里,我们将观测对象的大小在不断添加实例变量时增长(同样,使用ObjectSpace.memsize_of判别):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
require "objspace"
class Foo
def initialize
@a = 1
p ObjectSpace.memsize_of(self)
@b = 1
p ObjectSpace.memsize_of(self)
@c = 1
p ObjectSpace.memsize_of(self)
@d = 1
p ObjectSpace.memsize_of(self)
@e = 1
p ObjectSpace.memsize_of(self)
@f = 1
p ObjectSpace.memsize_of(self)
@g = 1
p ObjectSpace.memsize_of(self)
@h = 1
p ObjectSpace.memsize_of(self)
end
end
puts "First"
Foo.new
puts "Second"
Foo.new
以下是该程序的输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ ruby ~/thing.rb
First
40
40
40
80
80
96
96
120
Second
40
40
40
80
80
96
96
104
可以看到,当我们向对象不断添加实例变量时,对象内存会逐渐变大!
让我们对测试进行更改,然后再次运行。这一次,我们将添加一个选项(eager_h),让我们可以首先设置”最后一个”实例变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
require "objspace"
class Foo
def initialize eager_h
if eager_h
@h = 1
end
@a = 1
p ObjectSpace.memsize_of(self)
@b = 1
p ObjectSpace.memsize_of(self)
@c = 1
p ObjectSpace.memsize_of(self)
@d = 1
p ObjectSpace.memsize_of(self)
@e = 1
p ObjectSpace.memsize_of(self)
@f = 1
p ObjectSpace.memsize_of(self)
@g = 1
p ObjectSpace.memsize_of(self)
@h = 1
p ObjectSpace.memsize_of(self)
end
end
puts "First"
Foo.new false
puts "Second"
Foo.new true
输出如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ ruby ~/thing.rb
First
40
40
40
80
80
96
96
120
Second
104
104
104
104
104
104
104
104
在第一次分配内存时,我们可以观测到对象的大小像往常一样逐渐增长。 然而,在第二次分配时,我们要求它优先设置@h,其增长模式完全不同。事实上,它根本不再增长!
由于@h是索引表中的最后一个实例变量,Ruby 会立即对数组列表进行扩容,以便设置@h蛹的值。 由于实例变量数组现在处于最大容量,因此后续实例变量的设置都不需要再对数组进行扩容。
回到文章开头的基准测试(Back To Our Initial Benchmark)
每次Ruby需要扩张实例变量数组时,它都需要调用realloc来扩张该内存块。我们可以使用dtrace观察对realloc的调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Foo
def initialize forward
forward ? go_forward : go_backward
end
ivars = ("a".."zz").map { |name| "@#{name} = 5" }
# define the go_forward method
eval "def go_forward; #{ivars.join("; ")} end"
# define the go_backward method
eval "def go_backward; #{ivars.reverse.join("; ")} end"
end
# Heat
Foo.new true
if ARGV[0]
1000.times { Foo.new false }
else
1000.times { Foo.new true }
end
在这里,我对基准测试进行了调整,以便我们可以通过环境变量控制其执行方向。让我们使用dtrace来测量在这两种情况下分别对realloc的调用次数。
这种情况是总由前往后执行:
1
2
3
4
5
$ sudo dtrace -q -n 'pid$target::realloc:entry { @ = count(); }' -c "/Users/aaron/.rbenv/versions/ruby-trunk/bin/ruby thing.rb"
dtrace: system integrity protection is on, some features will not be available
8369
下例,由前往后一次,其余则由后往前执行:
1
2
3
4
5
$ sudo dtrace -q -n 'pid$target::realloc:entry { @ = count(); }' -c "/Users/aaron/.rbenv/versions/ruby-trunk/bin/ruby thing.rb reverse"
dtrace: system integrity protection is on, some features will not be available
4369
我们可以看到,”由后往前”显著减少了realloc的调用次数。 这些对realloc的调用次数的减少,就是为什么由前往后设置一次实例变量,其余由后往前设置实例变量会更快的原因!
我希望这是一篇有趣的文章。玩的开心!